Don't build (just) a RESTful API
By Miha Hribar | | 3 minute read
I recently had a talk at a local developer meetup about the state of APIs that sparked an interesting conversation. In the talk I outlined a few guidelines for building RESTful APIs, but stressed that even building everything according to all common practices is not enough anymore. Simply put, our APIs are too simple.
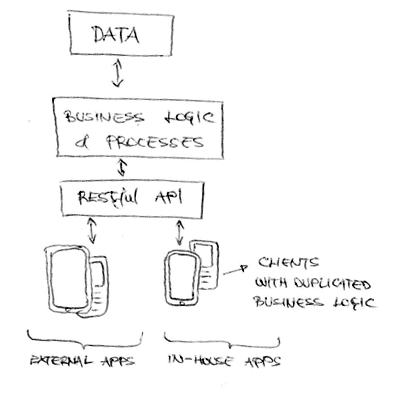
Don’t get me wrong. Building an API so other developers can access your data is great, and a RESTful approach is perfect for that. But for in-house apps a RESTful API is simply not enough.
Simple data, complex client
To build an API we usually type-marshal/serialize our objects, create special media types for each and smack a CRUD(Create Read Update Delete) interface on top of it. We then create our clients by connecting to our API and pulling in the JSON object representations and store them on the client.
Since not all mobile devices are online all the time, we are forced to port some of the business logic to the clients, and since in some cases using a product like Phone Gap might not cut it, we are forced to implement the same logic on multiple devices.
What we are left with is simple data coming in from the API and complex duplicated logic on all our clients.
Shouldn’t that be the other way round?
Complex data, simple client
In my search for a better way to build our API at Toshl I came across Building Hypermedia APIs with HTML5 and Node by Mike Amundsen. This is probably the best quote from the book:
The World Wide Web is fundamentally a distributed hypermedia application.
Think of the browser as the client, HTML as the message format and websites as the API. If a website is updated, the client doesn’t break, it just downloads the new content and displays it. Why don’t we build clients this way?
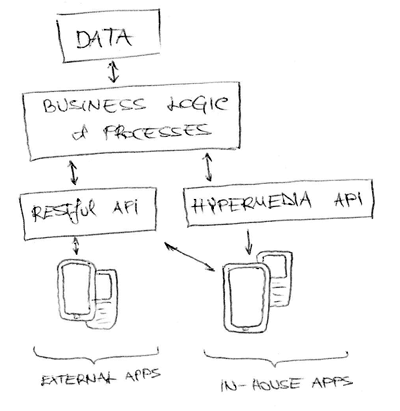
If we extend our JSON representation to include all the necessary information we need in our clients to work properly without breaking, our lives as developers would be much simpler.
The idea is that the client would still interact with the RESTful API, but instead of exposing just the data, we expose the processes and how the client is to interact with the API.
Example
Let’s take a look at a simple example: adding a new object on the client. The client would download everything it needs to present a form on the client. The form information would include all the fields, field options, validation, translations and how to construct a request to our API when the user completes the form.
When we change our process on the server, by lets say, adding a field or changing any of the field options, the client would just download the new information and redisplay the form.
There would still be times when we would have to fix the client, but only in extreme situations.
Conclusion
You might think that building a client this way would be too complicated, but all the client needs to do is display the data and learn how to interact with our API (in essence how to create a POST, GET, PUT or DELETE requests). That should not be that difficult.
I think this is the way the web is supposed to work. Truly distributed and extendable. I still hope that eventually everything will be able to be run on HTML, Javascript and CSS, but until then we are stuck with building APIs. Let’s make them smarter, so we can simplify our clients.